设计目标
基本架构
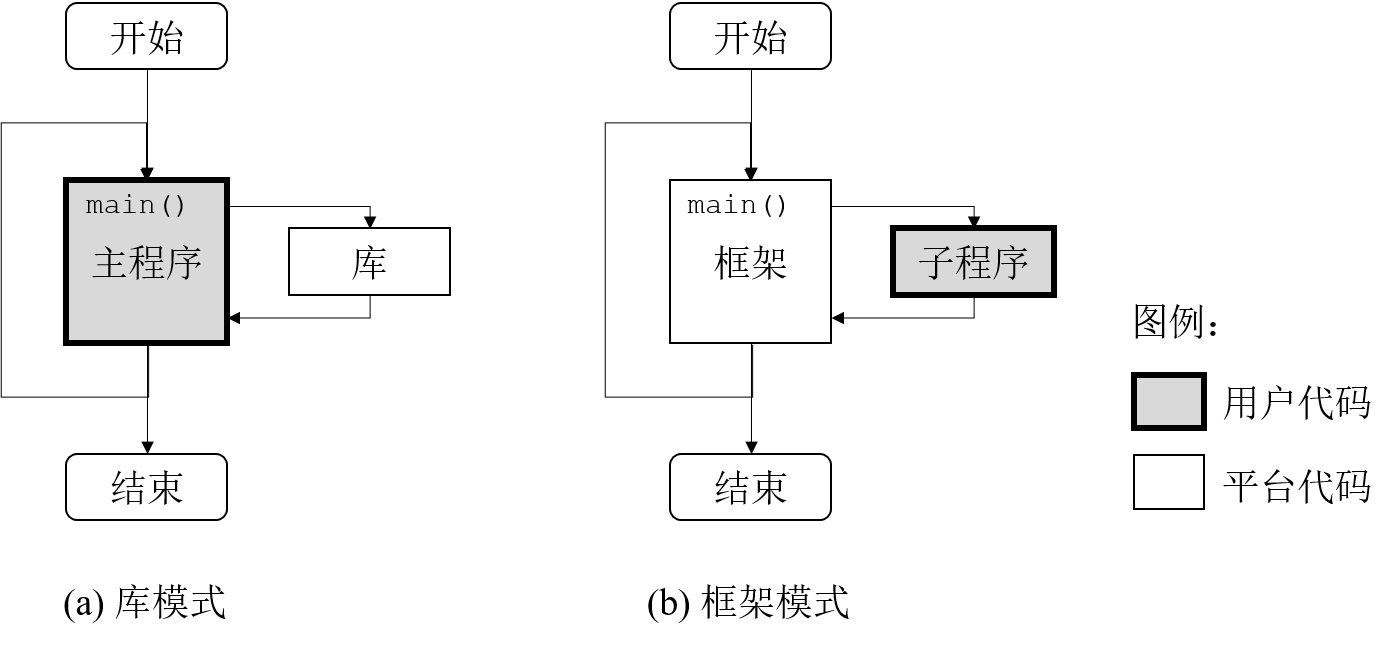
工作形态
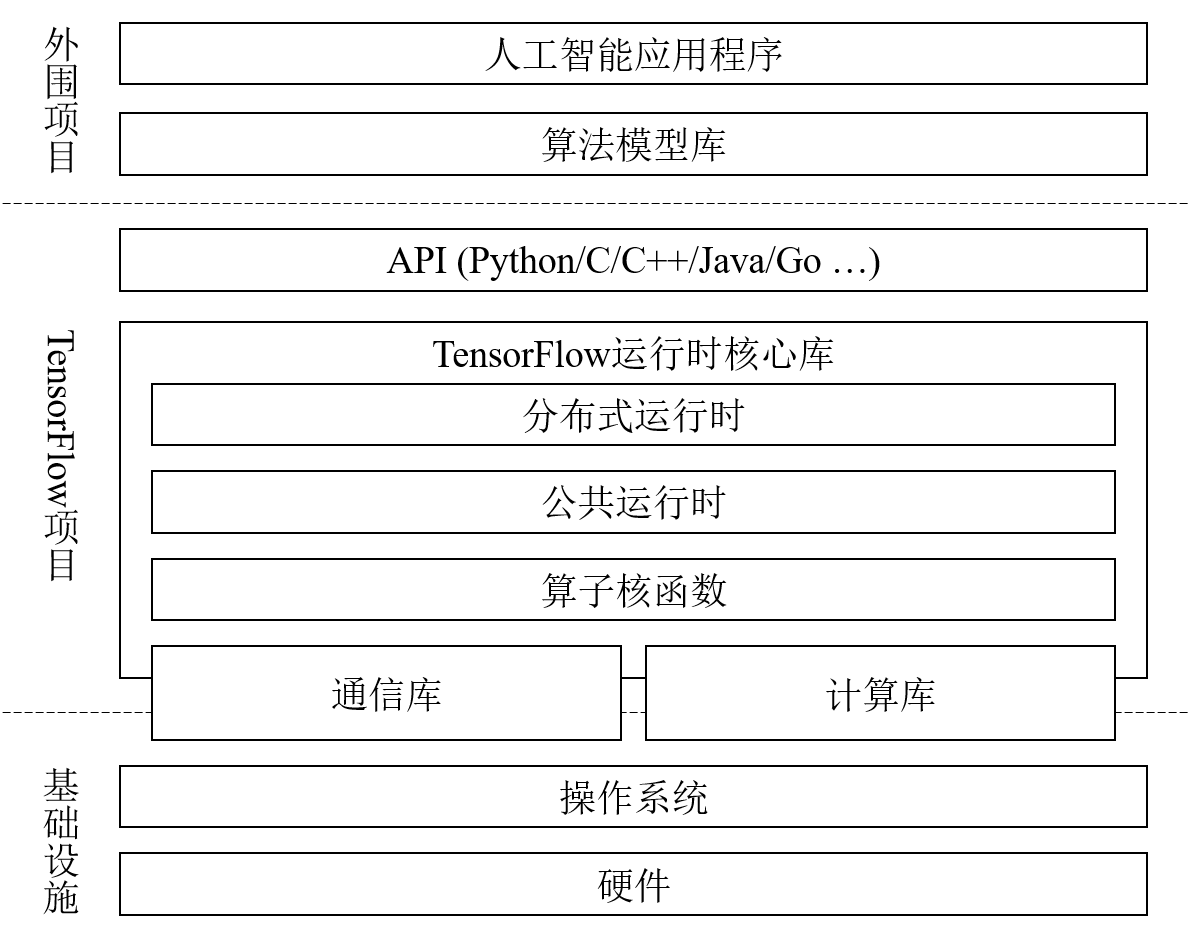
组件架构
设计原则
- Dataflow graphs of primitive operators(用原始的op,+,-之类的,而不是复杂的layer操作)
- Deferred execution (延迟执行,定义和执行分开)
- Common abstraction for heterogeneous accelerators
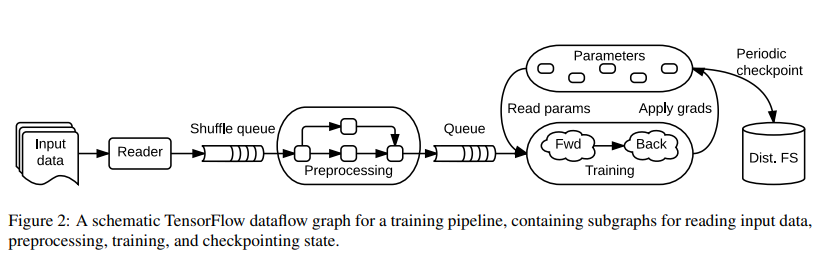
示例

# 1. Construct a graph representing the model.
x = tf.placeholder(tf.float32, [BATCH_SIZE, 784]) # Placeholder for input.
y = tf.placeholder(tf.float32, [BATCH_SIZE, 10]) # Placeholder for labels.
W_1 = tf.Variable(tf.random_uniform([784, 100])) # 784x100 weight matrix.
b_1 = tf.Variable(tf.zeros([100])) # 100-element bias vector.
layer_1 = tf.nn.relu(tf.matmul(x, W_1) + b_2) # Output of hidden layer.
W_2 = tf.Variable(tf.random_uniform([100, 10])) # 100x10 weight matrix.
b_2 = tf.Variable(tf.zeros([10])) # 10-element bias vector.
layer_2 = tf.matmul(layer_1, W_2) + b_2 # Output of linear layer.
# 2. Add nodes that represent the optimization algorithm.
loss = tf.nn.softmax_cross_entropy_with_logits(layer_2, y)
train_op = tf.train.AdagradOptimizer(0.01).minimize(loss)
# 3. Execute the graph on batches of input data.
with tf.Session() as sess: # Connect to the TF runtime.
sess.run(tf.initialize_all_variables()) # Randomly initialize weights.
for step in range(NUM_STEPS): # Train iteratively for NUM_STEPS.
x_data, y_data = ... # Load one batch of input data.
sess.run(train_op, {x: x_data, y: y_data}) # Perform one training step.
Reference
TensorFlow: A System for Large-Scale Machine Learning